یک جایگزین در CCA برای یادگیری یک فضای تعبیه مشترک با استفاده از SGD با از دست دادن(تلفات) رتبه بندی است. WSABIE و DeVISE [11] تبدیل های خطی از ویژگی های بصری و متنی را در فضای مشترک با استفاده از یک تلفات (دست دادن) رتبه بندی تک جهته بدست آوردند که یک جریمه مبتنی بر حاشیه را به حاشیه نویسی نادرست اعمال می کند که نسبت به آنهایی که برای هر تصویر آموزشی درست هستند، رتبه بندی بالاتری دارد. در مقایسه با روش های مبتنی بر CCA، تلفات رتبه به راحتی مقادیر زیادی از داده ها را با بهینه سازی تصادفی در آموزش، مقیاس بندی می کند. به عنوان یک تابع هدف قدرتمند تر، چند اثر دیگر یک تلفات رتبه بندی دو جهته را پیشنهاد دادند که، علاوه بر تضمین این که جملات صحیح برای هر تصویر آموزش رتبه بالایی از آنهایی که اشتباه هستند را بدست آورده است، همچنین تضمین می کند که برای هر جمله، تصویر توسط این جمله شرح داده می شود. رتبه تصاویر بالایی که توسط دیگر جملات شرح داده شده است، بدست می آورد [22، 23، 25، 43]. با این حال، در طول تاریخ، آن ثابت کرده است که به طور خنثی در تداخل CCA با یک تعبیه(کد های جاسازی) از AN-SGD بدست آمده دشوار است: کلاین و همکاران [26] نشان داده اند که به درستی نرمالیزه نمودنCCA در بالای ویژگی های قبلی تصویر و متن است، که به طور قابل توجهی بهتر می تواند در مدل های پیچیده تر عمل کند. مسیر دیگر پژوهش در تعبیه های با چند مقید (مودال) بر مبنای یادگیری عمیق است[3، 24، 25، 31، 35، 44]، که با استفاپده از روش هایی مانند ماشین بولتزمن عمیق [44]، خود رمز گذار [35]، LSTM ها، و شبکه های عصبی بازگشتی است [31، 45]. با ساخت آن ممکن است نگاشت های غیر خطی را یاد بگیرند، روش های عمیق می توانند در اصل توان نمایشی بزرگتری نسبت به روش مبتنی بر پیش بینی های خطی ارائه دهند [11، 15، 26، 49]. در این کار، ما یادگیری یک تعبیه تصویر متن را با استفاده از یک شبکه عصبی دو دید گاهه با دو لایه غیر خطی در بالای هر نمایش از تصویر و نمایش متن پیشنهاد می کنیم (شکل 1). این نمایش ها را می توان با توجه به خروجی های دو شبکه از قبل بدست آمده، در دسترس بودن ویژگی استخراج کننده، یا بدست آمده به طور مشترک سر به سر با تعبیه، ارائه داد. برای بدست آوردن این شبکه، ما از تابع تلفات دو جهته مشابه استفاده می کنیم [22، 23، 25، 43]، که همراه با محدودیت هایی است که ساختار مجاور را در داخل هر مشاهده فردی حفظ می کند. به طور خاص، در فضای نهفته مشخص شده، ما تصاویر (محدوده جملات) با معنای مشابه که نزدیک به یکدیگر هستند را می خواهیم. چنین محدودیت هایی از حفظ ساختار به طور گسترده در ادبیات یادگیری متریک بررسی شده است [19، 32، 40، 41، 48، 53]. به طور خاص، روش نزدیک ترین مجاور حاشیه بزرگ (LMNN) [48] تلاش می کند تا اطمینان حاصل شود که برای هر تصویر، همسایگان هدف(مدنظر) خود از کلاس یکسان نسبت به نمونه های کلاس های دیگر نزدیک تر باشد. همانطور که پژوهش ما نشان می دهد، این محدودیت ها همچنین می توانند یک عبارت تنظیم مفیدی برای تطبیق وظیفه مشاهده متقابل ارائه دهند.
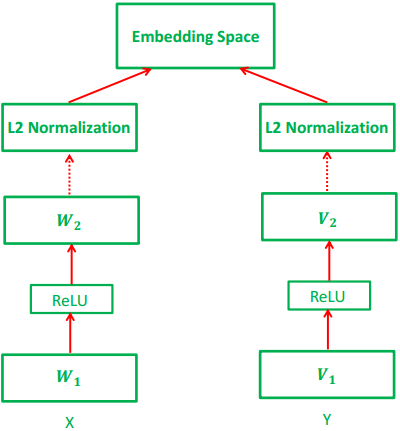
شکل 1. ساختار مدل ما: دو شاخه در شبکه وجود دارد، یکی برای تصاویر (X) و دیگری برای متن (Y). هر شاخه متشکل از لایه های به طور کامل متصل با غیر خطی های ReLU که بین آنها ایجاد می شود، که با استفاده از نرمالیزه کردن L2 در انتها دنبال می شود.